Dalam lanskap aplikasi cloud-native saat ini, tekanan untuk menghadirkan fitur dengan cepat sambil menjaga stabilitas antipeluru semakin tinggi. Tim teknik terus-menerus menyeimbangkan kebutuhan akan kecepatan dengan kebutuhan waktu aktif. Pergeseran ini memerlukan model operasional baru, yang membawa konsep seperti DevOps dan SRE ke garis depan pengembangan perangkat lunak modern.
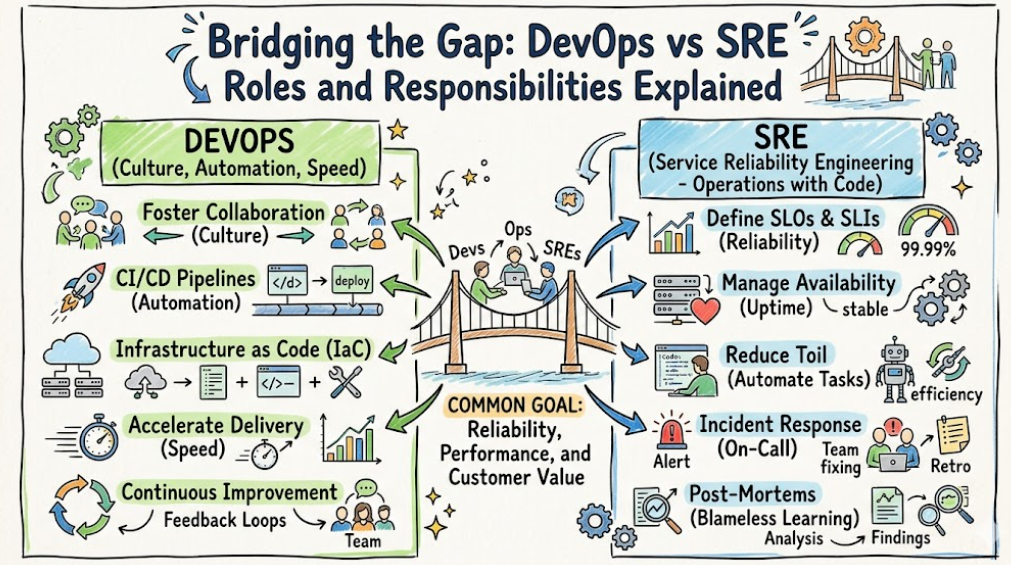
DevOps berfokus pada menghilangkan silo organisasi untuk memungkinkan pengiriman perangkat lunak yang lebih cepat dan andal. Sebaliknya, Site Reliability Engineering (SRE) mengambil prinsip yang sama dan menerapkannya melalui sudut pandang insinyur perangkat lunak, dengan fokus utama pada keandalan dan skalabilitas sistem. Bagi mereka yang ingin menguasai disiplin ilmu ini, DevOpsSchool menyediakan sumber daya yang komprehensif untuk menavigasi bidang yang kompleks ini.
Apakah Anda seorang pengembang yang ingin memahami pengoperasian atau seorang insinyur yang ingin berspesialisasi dalam keandalan, memahami nuansanya DevOps vs SRE sangat penting. Metodologi-metodologi ini tidak eksklusif satu sama lain; melainkan merupakan pendekatan yang saling melengkapi yang menentukan cara perusahaan modern mengelola infrastruktur, kode, dan, yang paling penting, pengalaman pengguna.
DevOps adalah serangkaian praktik, filosofi, dan alat yang meningkatkan kemampuan organisasi untuk menghadirkan aplikasi dan layanan dengan kecepatan tinggi. Pada intinya, DevOps adalah tentang mengubah budaya. Hal ini bertujuan untuk menjembatani kesenjangan antara tim pengembangan (yang ingin mengirimkan kode) dan tim operasi (yang ingin menjaga sistem tetap stabil).
Dengan menggunakan otomatisasi CI/CD, tim dapat menguji dan menerapkan perubahan kode dengan lebih sering dan andal. Model kepemilikan bersama ini memastikan bahwa pengembang lebih terlibat dalam proses penerapan, sehingga mengurangi kejutan ketika kode mulai diproduksi. Ini pada dasarnya adalah tentang perbaikan berkelanjutan, kolaborasi, dan mengurangi gesekan antara meja pengembang dan server di pusat data.
Rekayasa Keandalan Situs, atau SRE, adalah praktik penggunaan pendekatan rekayasa perangkat lunak untuk memecahkan masalah operasi. Diciptakan oleh Google, prinsip inti SRE adalah “harapan bukanlah sebuah strategi.” SRE memperlakukan operasi sebagai masalah perangkat lunak.
SRE bertanggung jawab atas ketersediaan, latensi, kinerja, efisiensi, manajemen perubahan, pemantauan, tanggap darurat, dan perencanaan kapasitas layanan mereka. Mereka sangat bergantung pada Sasaran Tingkat Layanan (SLO) dan anggaran kesalahan untuk memutuskan kapan harus bergerak cepat dan kapan harus berhenti sejenak demi stabilitas. Ini adalah pendekatan proaktif untuk menjaga sistem terdistribusi yang kompleks tetap berjalan lancar.
Secara tradisional, pengembangan dan operasi dilakukan secara terisolasi. Pengembang akan “melemparkan kode ke luar batas” ke dalam operasional, sehingga menyebabkan peluncuran yang tidak tepat sasaran dan tertunda. DevOps muncul sebagai solusi untuk hal ini, dengan menekankan otomatisasi dan pergeseran budaya.
Seiring dengan bertambahnya skala sistem—beralih dari aplikasi monolitik ke layanan mikro yang kompleks—kebutuhan akan pendekatan operasional yang lebih ketat dan berbasis data menjadi jelas. Di sinilah SRE masuk. SRE pada dasarnya memberikan “cara melakukan” untuk “apa” yang didefinisikan oleh DevOps. Meskipun DevOps menetapkan visi untuk pengiriman yang lebih cepat, SRE memberikan ketelitian teknis untuk memastikan bahwa pengiriman dapat diandalkan.
Meskipun mereka memiliki tujuan yang sama, namun pelaksanaannya berbeda.
| Fitur | DevOps | SRE |
| Fokus Utama | Kecepatan dan kolaborasi budaya | Keandalan dan stabilitas sistem |
| Filsafat | Pola pikir/pendekatan budaya | Disiplin yang berpusat pada teknik |
| Kepemilikan | Tanggung jawab bersama untuk pengiriman | Tanggung jawab atas pelayanan kesehatan |
| Otomatisasi | Fokus pada saluran CI/CD | Fokus pada pengurangan kerja keras dan keandalan |
| Metrik | Throughput, frekuensi penerapan | SLO, SLI, Anggaran Kesalahan |
| Manajemen Insiden | Kolaborasi reaktif | Rekayasa Proaktif/Sistematis |
Kedua disiplin ilmu ini berakar kuat pada nilai-nilai fundamental yang sama:
- Pola Pikir Otomatisasi-Pertama: Keduanya menghindari pekerjaan manual dengan cara apa pun.
- Perbaikan Berkelanjutan: Keduanya mengutamakan pembelajaran dari kegagalan.
- Budaya Kolaborasi: Keduanya menekankan untuk menghilangkan silo komunikasi.
- Infrastruktur sebagai Kode: Keduanya memperlakukan infrastruktur sebagai perangkat lunak yang dapat diprogram.
- Fokus pada Skalabilitas: Keduanya dirancang untuk menangani pertumbuhan secara efisien.
- Kolaborasi: Menghilangkan hambatan antar tim.
- Otomatisasi CI/CD: Memastikan kode selalu dalam keadaan dapat diterapkan.
- Infrastruktur sebagai Kode (IaC): Mendefinisikan server dan jaringan melalui file konfigurasi.
- Umpan Balik Berkelanjutan: Memantau hasil penerapan secara real-time.
- Kepemilikan Bersama: Pengembang memiliki kode dalam produksi.
- Merangkul Risiko: Menggunakan Anggaran Kesalahan untuk menyeimbangkan kecepatan fitur dengan keandalan.
- SLO dan SLI: Menetapkan tujuan tingkat layanan yang jelas dan terukur.
- Menghilangkan Kerja Keras: Mengotomatiskan tugas operasional manual yang berulang.
- Observabilitas: Memahami kesehatan sistem melalui pemantauan mendalam.
- Respons Insiden: Post-mortem yang terstruktur dan tidak bercela setelah pemadaman listrik.
Siklus hidup DevOps adalah proses berulang:
- Rencana: Mendefinisikan fitur dan persyaratan.
- Kode: Mengembangkan aplikasi.
- Membangun: Kompilasi dan pengemasan.
- Tes: Menjalankan pemeriksaan kualitas otomatis.
- Rilis/Penerapan: Mendorong ke produksi.
- Operasikan / Pantau: Mempertahankan dan mengamati kinerja.
SRE fokus pada fase “Operasi dan Pantau” dengan pendekatan mendalam:
- Pemantauan: Menerapkan telemetri yang kuat (metrik, log, pelacakan).
- Peringatan: Menetapkan ambang batas berdasarkan SLO.
- Respons Insiden: Mengelola pemadaman melalui buku pedoman yang ditentukan.
- Analisis Akar Penyebab: Analisis yang tidak bercela tentang mengapa segala sesuatunya gagal.
- Perencanaan Kapasitas: Memastikan sistem dapat menangani beban di masa depan.
Pemantauan adalah tentang menanyakan “Apakah sistemnya sehat?” (Metrik/Peringatan). Observabilitas adalah tentang menanyakan “Mengapa sistem berperilaku seperti ini?” (Log, Jejak, Konteks).
DevOps sering kali mengandalkan pemantauan untuk memastikan penerapan berhasil. SRE menyelami kemampuan observasi untuk men-debug kegagalan layanan mikro yang kompleks. Alat umum meliputi Prometheus untuk metrik, Grafana untuk visualisasi, itu Tumpukan Rusa untuk manajemen log, dan anjing data untuk pemantauan cloud terpadu.
Otomatisasi adalah landasan dari kedua bidang tersebut. Di DevOps, otomatisasi berfokus pada jalur pengiriman perangkat lunak (Jenkins, GitLab CI). Di SRE, otomatisasi berfokus pada “Pengurangan kerja keras”—menghilangkan pekerjaan manual, berulang, dan taktis yang menghalangi para insinyur untuk mengerjakan proyek-proyek strategis.
Di dunia Kubernetcontainer, dan layanan mikro, batasan antara DevOps dan SRE sering kali kabur. Rekayasa platform muncul sebagai titik temu dari keduanya, di mana tim membangun platform pengembang internal layanan mandiri (IDP). Hal ini memungkinkan pengembang untuk menggunakan infrastruktur sebagai layanan, sementara SRE memastikan platform yang mendasarinya tetap andal dan terukur.
| Alat | Tujuan | Penggunaan Perusahaan | Kesulitan |
| Jenkins | CI/CD | Tinggi | Sedang |
| terraform | IaC | Tinggi | Sedang |
| Buruh pelabuhan | Kontainerisasi | Tinggi | Rendah |
| Mungkin | Konfigurasi | Sedang | Rendah |
| Alat | Tujuan | Penggunaan Perusahaan | Kesulitan |
| Prometheus | Pemantauan | Tinggi | Tinggi |
| Tugas Pager | Manajemen Insiden | Tinggi | Rendah |
| Gremlin | Rekayasa Kekacauan | Sedang | Tinggi |
| Grafana | Observabilitas | Tinggi | Sedang |
- Waktu ke Pasar Lebih Cepat: Fitur menjangkau pengguna dalam hitungan jam, bukan minggu.
- Moral Tim yang Lebih Baik: Lebih sedikit pekerjaan manual menghasilkan kepuasan kerja yang lebih tinggi.
- Kualitas Lebih Tinggi: Pengujian otomatis mendeteksi bug lebih awal.
- Mengurangi Waktu Henti: Tindakan keandalan yang proaktif mencegah pemadaman listrik.
- Keputusan Berdasarkan Data: SLO memberikan bahasa yang netral untuk produk dan teknik.
- Kecepatan Berkelanjutan: Mencegah kelelahan melalui pengurangan kerja keras secara sistematis.
- Perlawanan Budaya: Beralih dari model siled tradisional memang sulit.
- Kelelahan Alat: Mengadopsi terlalu banyak alat tanpa strategi yang jelas.
- Kesenjangan Keterampilan: Kedua bidang tersebut memerlukan pengetahuan mendalam seputar pengembangan dan operasi.
- Peringatan Kelelahan: Terlalu banyak peringatan positif palsu dapat menyebabkan kelelahan.
Keduanya menawarkan pertumbuhan karir yang luar biasa.
- Insinyur DevOps: Berfokus pada pipeline, CI/CD, dan otomatisasi infrastruktur.
- Insinyur Keandalan Situs: Berfokus pada arsitektur sistem, keandalan, dan respons insiden.
- Insinyur Platform: Membangun infrastruktur dan alat yang memungkinkan pengembang bekerja secara efisien.
Pembelajaran langsung adalah yang terpenting. Menguasai Linux, jaringan, dan platform cloud (AWS, Azure, GCP) adalah dasarnya.
| Sertifikasi | Terbaik Untuk | Daerah Fokus |
| CKA (Administrator Kubernetes Bersertifikat) | Awan/SRE | Orkestrasi Kontainer |
| Profesional Insinyur AWS DevOps | DevOps | CI/CD berbasis cloud |
| Insinyur Cloud DevOps Profesional Google | Keduanya | Prinsip SRE |
Jelajahi jalur pembelajaran terstruktur di DevOpsSchool untuk membangun kompetensi penting ini.
- Perkakas Atas Prinsip: Mempelajari suatu alat tanpa memahami konsep yang mendasarinya.
- Mengabaikan Dasar-Dasar: Melewatkan dasar-dasar Linux, jaringan, atau dasar-dasar basis data.
- Mengabaikan Dokumentasi: Dengan asumsi Anda bisa mengetahuinya nanti.
- Kurangnya Otomatisasi: Melakukan sesuatu secara manual “sekali ini saja.”
Masa depan menunjuk ke arah AIOps (menggunakan AI untuk memprediksi kegagalan), GitOps (mengelola infrastruktur melalui alur kerja Git), dan Rekayasa Platform. Ketika sistem menjadi lebih terdistribusi, fokusnya akan beralih dari “sistem pemantauan” menjadi “mengelola keandalan dalam skala besar.”
- Apa perbedaan antara DevOps dan SRE? DevOps adalah kerangka budaya, sedangkan SRE adalah implementasi praktis dari rekayasa keandalan.
- Apakah SRE bagian dari DevOps? SRE sering kali dianggap sebagai implementasi spesifik atau “bagian” dari prinsip-prinsip DevOps.
- Mana yang lebih baik: DevOps atau SRE? Tidak ada yang lebih baik; mereka melayani tujuan operasional yang berbeda.
- Apakah SRE memerlukan pengkodean? Sangat. SRE menggunakan rekayasa perangkat lunak untuk menyelesaikan tugas operasi.
- Apakah Kubernetes penting untuk SRE? Ya, ini adalah standar untuk mengelola infrastruktur cloud-native dalam skala besar.
- Apa itu SLO dan SLI? SLI adalah metrik yang Anda ukur; SLO adalah target yang Anda tuju.
- Apakah SRE membuat stres? Bisa saja, tetapi tim SRE yang matang menggunakan anggaran kesalahan dan otomatisasi untuk mengelola tekanan tersebut.
- Karier mana yang memiliki pertumbuhan lebih baik? Keduanya adalah peran yang banyak diminati dengan kompensasi yang sangat baik.
- Apakah saya perlu menjadi pengembang untuk DevOps? Anda memerlukan keterampilan skrip dan otomatisasi yang kuat.
- Bagaimana saya memulainya? Mulailah dengan Linux, Git, dan penyedia cloud.
- Bisakah DevOps ada tanpa SRE? Ya, tetapi keandalan mungkin akan menurun dalam skala besar.
- Bisakah SRE ada tanpa DevOps? Hal ini sulit dilakukan, karena SRE bergantung pada budaya kolaborasi yang ditentukan oleh DevOps.
- Apakah gaji di bidang ini tinggi? Ya, karena peran-peran ini sangat penting untuk kelangsungan bisnis modern.
- Keterampilan apa yang paling penting? Pemecahan masalah dan kemampuan untuk mempelajari teknologi baru.
- Apakah ada perbedaan dalam respon insiden? SRE menekankan pemeriksaan mayat yang didukung data dan otomatisasi pencegahan.
Sukses dalam bidang teknik modern bukan tentang memilih antara DevOps dan SRE; ini tentang mengintegrasikan yang terbaik dari keduanya. DevOps memberikan ketangkasan budaya, sementara SRE menyediakan disiplin teknik yang diperlukan untuk meningkatkan ketangkasan tersebut tanpa merusak sistem. Fokus pada penguasaan dasar-dasarnya, terapkan otomatisasi, dan selalu prioritaskan observabilitas.
Temukan Rumah Sakit Jantung Terpercaya
Bandingkan rumah sakit jantung berdasarkan kota dan layanan — semuanya di satu tempat.
Jelajahi Rumah Sakit
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.